
Machine Learning – Dawn of Artificial Intelligence
Classification
The focus of this blog will be the difference between artificial intelligence and machine learning. As a quick detail before the start, we know about both supervised and unsupervised learning, with them both being subsets of the field of machine learning. Supervised learning is when we have labeled, structured data, and the algorithms we are using determine the output based on the input data. Unsupervised learning, on the other hand, is for unlabeled, unstructured data, where our algorithms of choice are tasked with deriving structure from unstructured data to be able to predict output data based on input data. Additionally, both supervised and unsupervised learning is further subsections.
1. Regression,
A supervised learning approach where the output is the value of a feature based on the correlation with another feature, that being on a continuous line of best fit our algorithm determines.
2. Classification, a supervised learning approach where the output is the label of a data point based on the category the point was in. There are a number of discrete categories whose decision boundaries are determined based on the algorithm we choose.
3. Clustering, an unsupervised learning approach where we must discover the categories’ various data points line based on the relationships of their features.
4. Association, an unsupervised learning approach where we must discover the correlations of features in a dataset.

As stated, while it is nice to view these topics in their own little bubbles, often, there’s a lot of crossover between various techniques, for instance, in the case of semi-supervised learning. This wasn’t discussed previously, but it is essential when our dataset contains both labeled and unlabeled data, so on this instance, when we have both these types of data, we may first cluster the data and then run classification algorithms on it or a multitude of other combinations of techniques. So now, a general understanding of the types of machine learning, and the knowledge of all the terminology we have covered, we can now begin to decipher what the term machine learning really means, and how it relates to artificial intelligence in other fields. As we know, the term machine learning was coined by computing pioneer Arthur Samuel and is a field of study that gives computers the ability to learn without being explicitly programmed. With such a broad definition, one can argue and would be correct in stating, that all useful programs learn something. However, the level of true learning varies. This level of learning is dependent on the algorithms the programs incorporate. Now, going back a few steps, an algorithm is a concept that has existed for centuries, since the dawn of human civilization. It is a term referring to a process or set of rules to be followed in calculations or other problem-solving operations. While anything can be referred to as an algorithm, such as a recipe for a food dish or the steps needed to start a fire, it is a term most commonly used to describe our understanding of mathematics, and how it relates to the world around us, the informational fabric of reality.
ALGORITHMS OF MACHINE LEARNING
Progressing forward, with the rising of computing, essentially a field built on the premise of speeding up mathematical calculations, gave way to the birth of computer science in which algorithms now define the processing, storing, and communication of digital information. The ability to iterate through algorithms at the lightning-fast speed computers operate at over the past century has led to the implementation and discovery of various algorithms. To list a few, we have sorting algorithms like bubble sort and quick sort, shortest path algorithms like Dijkstra and A*, and this list can go on and on for a variety of problems. These algorithms, while able to perform tasks they appear to be learning, are really just iteratively performing pre-programmed steps to achieve the results, in stark contrast to the definition of machine learning, to learn without explicit programming. As we know the types of machine learning, both supervised and unsupervised, there’s one common thread that runs through them both, to utilize a variety of techniques, approaches, and algorithms to form decision boundaries over a dataset’s decision space. This divided up decision space is referred to as the machine learning model, and the process of forming the model, that being the decision boundaries in the dataset, is referred to as training. This training of the model draws parallels to the first primary type of knowledge we as humans display, declarative knowledge. In other words, memorization, the accumulation of individual facts. Once we have a trained model and it is exhibiting good accuracy on training data, then we can use that model for the next step, inference. This is the ability to predict the outputs, whether that be a value ora category, of new data.

Machine learning inference draws parallels to the second primary type of knowledge we exhibit, imperative knowledge, in other words, generalization, the ability to deduce new facts from old facts. Additionally, as the model encounters new data, it can use it to train further, refining its decision boundaries to become better at inferring future data. Now, this whole process we just discussed is defining the second most widely-used definition of machine learning, stated by Dr. Tom Mitchell of Carnegie Mellon University. A computer is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T as measured by P improves with experience E. So, while it is correct in stating that all useful programs learn something from data, I hope the distinction between the level of learning machine learning models and typical algorithms is now more clear. The rise of machine learning, domain-specific weak artificial intelligence, as it is referred to, has been decades in the making.
ARTIFICIAL INTELLIGENCE – SNEAK PEEK
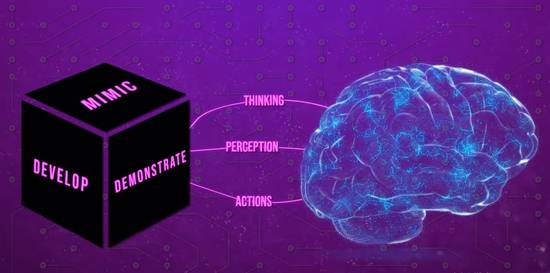
But first, what is artificial intelligence? AI refers to any model that can mimic, develop, or demonstrate human thinking, perception, or actions. In our case, this refers to computing-based AI, we saw the development of the field of artificial intelligence from trying to develop a more general AI, also called a strong AI, to focusing on acquiring domain-specific expertise in various fields. This turning point in the field of AI was due to expert systems in the ’80s, essentially complex conditional logic, that being if-then-else statements that were tailored for a respective field of knowledge by experts in that field. At the end of that birth of AI video, the time period we left off on was the AI bust, which was at the start of the ’90s, a low point in the AI hype cycle due to over-promises made on what expert systems could really do. After this point, the development of intelligent systems went into the background due to the lack of funding and mainstream interest in the field, and the rapid technological progress made in so many other fields, from the invention of the internet, commercialization of computers, mobile phones. The list can go on and on. During this time period in the ’90s, expert systems and algorithms originally developed by AI researchers began to appear as parts of larger systems. These algorithms had solved a lot of very difficult problems, and their solutions proved to be useful throughout the technology industry, such as data mining, industrial robotics, logistics, speech recognition, banking software, medical diagnosis, and Google’s search engine, to list a few. However, the field of AI received little or no credit for these successes in the 1990s and early 2000s. Many of the fields of AI’s greatest innovations had been reduced to the status of just another item in the tool chest of computer science.
5 TRIBES OF MACHINE LEARNING
As Nick Bostrom, author of “Superintelligence,” stated in 2006, “A lot of cutting-edge AI has filtered “into general applications, often without being called AI “because, once something becomes useful enough “and common enough, it is not labeled AI anymore.” This is similar to what John McCarthy, the father of AI, also stated back in the ’80s. So then, what started changing in the late 2000s and at the start of this decade that propelled the field of AI once again to the forefront? Well, first off, we can thank the increase of computing power and storage, infinite computing, big data, and various other topics we’ve covered in videos past. These advances allowed for larger amounts of data to train on, and the computing power and storage needed to be able to do so. Now, one can say that finding structure in data is a human condition. It’s how we’ve come so far, and these advances gave computers what they require to do so as well. Now, as you can see here, the difference between various AI breakthroughs and the date the algorithm was initially proposed is nearly two decades. However, on average, just three years after the dataset for a set problem becomes available does the breakthrough happen, meaning that data was a huge bottleneck in the advancement of the field of AI. The next reason for the rise of machine learning is due to the rise of a particular tribe of machine learning, connectionism, or, as many commonly know of it, deep learning. Before we delve into deep learning, let’s first discuss the other tribes of AI. There are five primary tribes of machine learning, with tribes referring to groups of people who have different philosophies on how to tackle AI-based problems.

The first tribe is the symbolists. They focus on the premise of inverse deduction. They don’t start with a premise to work towards conclusions, but rather use a set of premises and conclusions, and work backward to fill in the gaps. The second tribe is the connectionists. They mostly try to digitally-reengineer the brain and all of its connections in a neural network. The most famous example of the connectionist approach is what is commonly known as deep learning. The third tribe is the revolutionaries. Their focus lies in applying the idea of genomes in DNA and the evolutionary process to data processing. Their algorithms will constantly evolve and adapt to unknown conditions and processes. You have probably seen this style of the approach used in beating games such as Mario. The fourth tribe is the Bayesians. Bayesian models will take a hypothesis and apply a type of a priori thinking, believing that there will be some outcomes that are more probable. They then update their hypothesis as they see more data. The fifth and final tribe is the analogies. This machine learning tribe focuses on techniques to match bits of data to each other. How I think it would be best to represent these tribes of artificial intelligence and machine learning is ina bubble diagram format. To start with, we have our primary AI bubble and machine learning bubble. We show this relationship in the first video in our machine learning series. Now, after this, we can add the tribe bubbles. They are constantly moving and overlapping with each other to produce novel ideas, and shrinking and growing in popularity. Once a tribe gets mainstream popularity, such as connections, it pops, so to speak, producing a new field in its wake. In the case of connections, it was deep learning. Keep in mind that, just because the connectionism grows into deep learning doesn’t mean that the entire tribe of connectionism is centered around deep learning. The connectionism bubble and many connectionists will continue researching new approaches utilizing the connectionist theory. Also, deep learning isn’t all connectionism. There are many symbolist and analogist philosophies incorporated within it as well. You can learn more about the five tribes of machine learning in Pedro Domingos’ book “The Master Algorithm,” which goes very in-depth into the topics we just talked about, and also goes over topics we will cover in future videos in this series.

CONCLUSION – DIFFERENCE BETWEEN MACHINE AND ARTIFICIAL INTELLIGENCE?
Coming back on topic, so then, what is the difference between machine learning and artificial intelligence? Nothing and everything. While machine learning is classified as a type of AI since it exhibits the ability to match and even exceed human-level perception and action in various tasks, it, as stated earlier, is a weak AI since these tasks are often isolated from one another, in other words, domain-specific. As we’ve seen, machine learning can mean many things, from millions of lines of code with complex rules and decision trees to statistical models, symbolist theories, connectionism and evolution-based approaches, and much more, all with the goal to model the complexities of life, just as how our brains try to do. With the advent of big data, the increases in computing power and storage, and the other factors we discussed earlier and in videos past took these models from simpler iterative algorithms to those involving many complex domains of mathematics and science working together in unison, such as knot theory, game theory, linear algebra, and statistics, to list a few. One important note to touch on with these models, no matter how advanced the algorithms used, is best said through a quote by famous statistician George Box, “All models are wrong, but some are useful.” By this, it is meant that, in every model, abstractions and simplifications are made such that they will never 100% model reality. However, simplifications of reality can often be quite useful in solving many complex problems. Relating to machine learning, this means we will never have a model that has an accuracy of 100% in predicting an output inmost real-world problems, especially in more ambiguous problems. Two of the major assumptions made in the field of machine learning that is a cause of this is that one, we are assuming that the past, that being the patterns of the past, predict the future, and two, that mathematics can truly model the entire universe. Regardless of these assumptions, these models can still be very useful in a broad array of applications.

![How to solve [pii_email_ca424a78d7aaf1280a80] error](https://www.factscoops.com/wp-content/uploads/2021/03/How-to-solve-pii_email_ca424a78d7aaf1280a80-error-390x205.jpg)

Thank you for this article. I’d personally also like to convey that it can always be hard if you find yourself in school and starting out to initiate a long credit score. There are many college students who are just trying to make it through and have a lengthy or favourable credit history can sometimes be a difficult factor to have.